



We are going to look How to Install Meta AI Audiocraft?, but lets talk about Meta AI. Meta AI (formerly known as Facebook AI) has developed an open-source text-to-speech (TTS) model called “Audiocraft.” Audiocraft is a deep learning-based model that can generate high-quality human-like speech from text inputs. This guide will walk you through the process of installing Meta AI Audiocraft on your local machine
Prerequisites installing Audiocraft
- Python 3.6 or higher
- PyTorch 1.6.0 or higher
- Torchaudio 0.6.0 or higher
- CUDA 10.2 or higher (if using a GPU)
Video Demo

How to Install Meta AI Audiocraft?
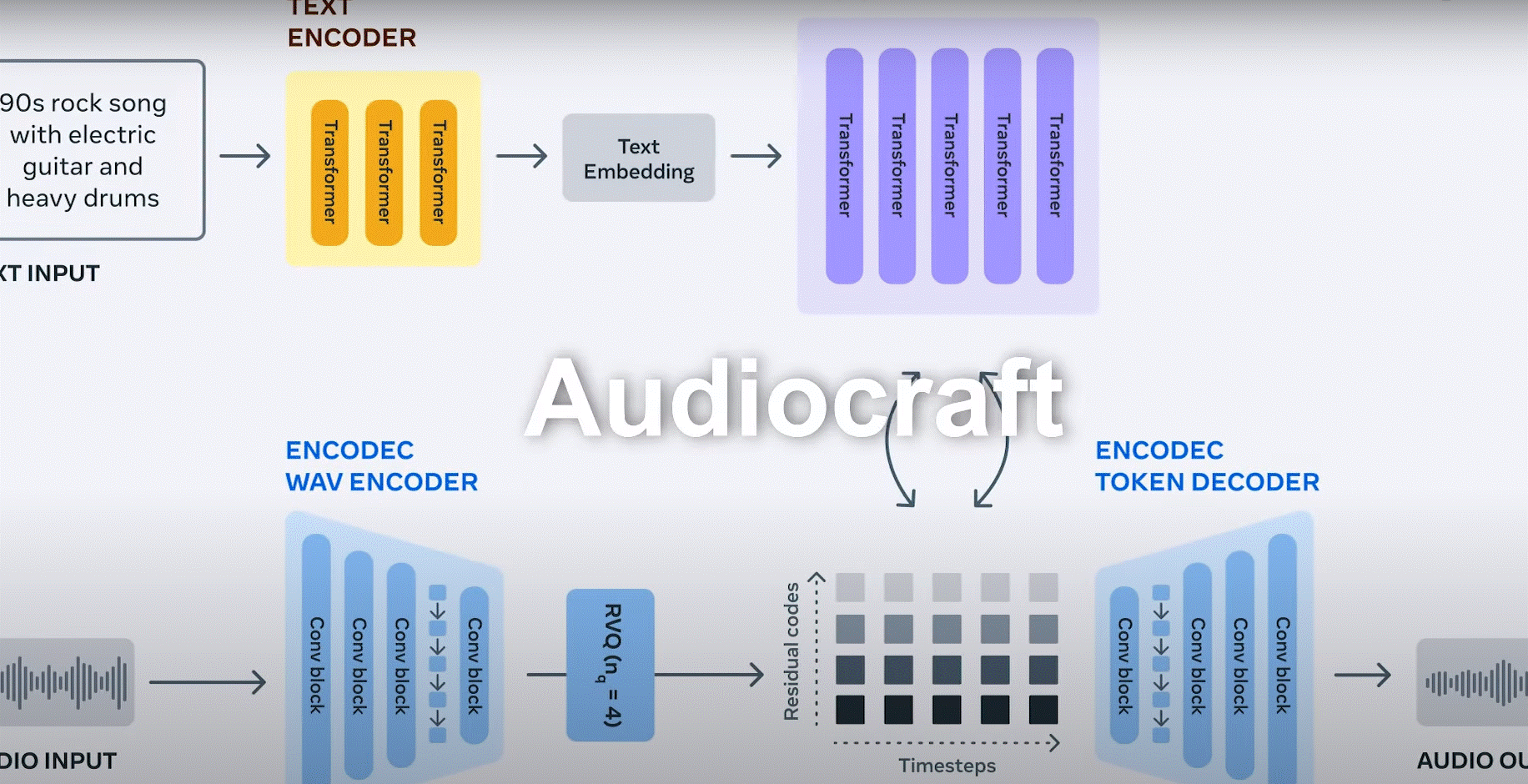
Step 1: Clone the Audiocraft Repository
First, clone the Audiocraft repository from Meta AI’s official GitHub page:
git clone https://github.com/facebookresearch/audiocraft.git
Step 2: Create a Python Virtual Environment (Optional)
Creating a virtual environment is recommended to isolate the Audiocraft dependencies from your system’s Python environment. To create a virtual environment, run the following commands: bash
python3 -m venv audiocraft_env
source audiocraft_env/bin/activate # On Windows, use `audiocraft_env\Scripts\activate`
Step 3: Install Audiocraft Dependencies
Next, navigate to the cloned Audiocraft repository and install the required dependencies using pip: bash
cd audiocraft
pip install -r requirements.txt
Step 4: Install Audiocraft
After installing the dependencies, install the Audiocraft package using the following command: bash
pip install .
Step 5: Verify the Installation
First, clone the Audiocraft repository from Meta AI’s official GitHub page: python
python examples/text_to_speech.py --text "Hello, Audiocraft!"
If the installation was successful, you should hear a generated audio file saying “Hello, Audiocraft!”Now you have successfully installed Meta AI Audiocraft on your local machine. You can start building text-to-speech applications using this powerful tool.For more information and detailed usage examples, refer to the official Audiocraft documentation: https://facebookresearch.github.io/audiocraft/
List of Pre-trained Models
Audiocraft provides the following pre-trained TTS models:
- Tacotron 2: An end-to-end generative model that learns to map text inputs to spectrograms and then synthesize speech from the spectrograms.
- FastSpeech 2: A text-to-speech model that generates mel-spectrograms from text inputs, followed by a separate vocoder to synthesize speech from the mel-spectrograms.
- WaveRNN: A high-quality neural vocoder that converts mel-spectrograms into raw audio waveforms.
Usage Examples
To use the pre-trained models, you can load them using the class and then generate speech from text inputs. Here’s an example using FastSpeech 2:
from audiocraft.TTSModel import TTSModel
# Load the pre-trained FastSpeech 2 model
model = TTSModel.from_pretrained("fastspeech2")
# Set the text input
text = "Hello, Audiocraft!"
# Generate the mel-spectrogram
mel_spectrogram = model.infer_mel_from_text(text)
# Use WaveRNN to convert the mel-spectrogram into raw audio
waveform = model.infer_waveform_from_mel(mel_spectrogram)
Congratulations, maestros of melody! With these effortlessly navigable steps, you’re on the brink of unlocking a symphony of creativity, immersing yourself in the boundless realm of musical wonders.
Embark on your enchanting musical odyssey with Meta AI Audiocraft, where every note is an invitation to orchestrate your dreams into reality. The world awaits the unveiling of your harmonious creations!
Should you find yourself entangled in the labyrinth of musical inspiration or wish to unveil your auditory masterpieces, don’t hesitate to grace us with your thoughts in the comments below. Here’s to crafting celestial tunes and happy music-making!






{kind=link}